install.packages("tidyverse")
library(tidyverse)Una guía práctica para empezar a analizar y graficar datos cuantitativos en R
Guía paso a paso para empezar a analizar y graficar datos cuantitativos en R. Carga de datos reales, exploración, transformación con tidyverse y visualización con ggplot2, explicadas de forma clara y aplicada.
Empezar a trabajar con datos cuantitativos suele generar una mezcla de entusiasmo y desconcierto. Hay números, tablas extensas, variables con nombres poco claros y una pregunta inicial que siempre vuelve: por dónde empezar. Acá te propongo un recorrido completo, pensado como una guía básica, que va desde la carga y exploración de datos hasta la producción de gráficos claros y reutilizables. El objetivo es mostrar un flujo de trabajo coherente, donde cada paso tenga sentido en relación con el anterior.
La idea no es agotar todas las posibilidades de R, sino ofrecer un mapa inicial para orientarse. A lo largo del texto vamos a trabajar con datos reales, funciones ampliamente utilizadas y decisiones analíticas habituales en investigaciones sociales y aplicadas.
1. Trabajar con datos reales desde el inicio
Una de las primeras decisiones importantes es con qué datos practicar. Usar datos reales tiene una ventaja clara: obliga a enfrentarse a problemas concretos, como valores faltantes, codificaciones poco transparentes o distribuciones desiguales.
Algunos datasets accesibles y muy utilizados para empezar son:
Encuesta Permanente de Hogares (EPH) de Argentina, accesible desde el paquete
ephde rOpenSci.gapminder, que reúne indicadores demográficos y económicos comparables entre países y años.
European Social Survey (ESS), una encuesta comparativa sobre actitudes y condiciones sociales.
En este recorrido voy a usar ejemplos inspirados en este tipo de datos, con variables como edad, nivel educativo, ingresos o indicadores de bienestar.
2. Cargar datos y preparar el entorno de trabajo
Lo primero que tenés que hacer es instalar R y RStudio, y eso lo podés ver en este post. R es el lenguaje de programación (el motor que ejecuta los comandos) y RStudio es la interfaz gráfica (técnicamente el entorno de desarrollo integrado) que permite ejecutar el código en R de forma más cómoda. Una vez que tengas todo instalado, abrí RStudio y familiarizate con los cuatro paneles: el editor de scripts arriba a la izquierda, la consola abajo a la izquierda, el entorno (environment) arriba a la derecha y el panel de archivos (files, plots…) abajo a la derecha. Si bien podés escribir y ejecutar todo tu código en la consola, te sugerimos que lo hagas en el editor de scripts, ya que así podrás guardarlo y volver a ejecutarlo en otro momento.
El código que tenés que escribir y ejecutar en esta guía lo vas a encontrar en recuadros grises. Si bien podés copiar y pegar cada línea de código en tu script, nuestra sugerencia es que escribas a mano los comandos, porque eso ayuda a incorporar la práctica de la programación. Los escribís en el editor de scripts (el panel que está arriba a la izquierda en RStudio) y los ejecutás haciendo control+enter (en Windows o Linux), command+enter (en macOS), o directamente apretando el botón que dice “Run”. Si no solés usar atajos de teclado (las combinaciones de teclas)1, te sugerimos que te acostumbres a hacerlo. Escribir código es una práctica intelectual, pero también es una práctica física: a medida que tu cuerpo se acostumbre a interactuar con la computadora para esta función, más fácil y natural te va a resultar todo.
El primer paso consiste en cargar los paquetes necesarios. En R, la mayor parte del trabajo exploratorio y gráfico se apoya en el ecosistema tidyverse (podés leer más sobre Tidyverse acá). Si ya tenés instalado el Tidyverse, podés saltearte la primera línea (el símbolo # sirve para “comentar” una línea entera y evitar que se ejecute; si necesitás ejecutarla, lo borrás y listo). Lo que sí hay que hacer siempre es cargar el paquete con la función library(). La instalación de tidyverse puede llevar unos minutos; además, va a mostrar una descripción de lo que hace en la consola, así que no te preocupes si aparece mucho texto en la consola (a menos que algo diga error, en ese caso hay que investigar qué está pasando).
Esto nos sirve para empezar a prestar atención a la sintaxis de R, es decir, a la forma en la que se escriben los comandos para ejecutar las acciones que necesitamos. En este caso, todas las palabras que aparezcan afuera de los paréntesis se denominan funciones y lo que aparece dentro de ellas son los argumentos de esas funciones, que son los elementos o los parámetros que debemos especificar para que esa función se ejecute. Por ejemplo, en el caso anterior, tenemos dos funciones: install.packages() y library(). La primera instala paquetes y la segunda los carga dentro de nuestra sesión actual de R. El argumento que toman ambas es el nombre del paquete: en el primer caso, se debe indicar el nombre entre comillas (porque es un elemento nuevo) y, en el segundo, sin comillas, porque es un elemento que ya está en la memoria de R y solo debemos traerlo a esta sesión en particular. Las funciones pueden tomar muchos argumentos distintos: algunos serán obligatorios, otros no. Podés aprender más sobre las funciones escribiendo ?install.packages, por ejemplo, en la consola: eso abre la documentación, es decir, la guía informativa sobre el funcionamiento de esa función.
Como mencionamos antes, tidyverse es un conjunto de paquetes que incluye herramientas para importar datos, transformarlos y visualizarlos. Además, vamos a usar el paquete gapminder como fuente de datos, por lo cual vamos a instalar el paquete, luego cargarlo, y construir un objeto a partir del dataset que incluye.
install.packages("gapminder", repos = "http://cran.us.r-project.org")
The downloaded binary packages are in
/var/folders/gx/n4drsz9j2c3b9dd6phbrgttr0000gn/T//RtmpnEG3mr/downloaded_packagesdatos <- gapminder::gapminderLa primera línea es idéntica a lo que hicimos con el paquete anterior. La segunda introduce una novedad: si necesitamos tomar solamente un elemento de ese paquete (como en este caso, que solamente necesitamos cargar un conjunto de datos), podemos llamar al elemento dentro del paquete usando los dos-dos puntos (::). El primer elemento es el nombre del paquete y el segundo es el nombre de la función o el elemento específico que queremos traer. Esto es útil cuando queremos controlar la cantidad de memoria que usamos, porque nos permite cargar solamente lo que necesitamos y no todo el paquete entero. También sirve para aquellos casos donde dos paquetes distintos tienen una función con el mismo nombre (que no es muy frecuente, pero ocurre): identificar el nombre del paquete desambigua qué función queremos usar.
En esta segunda línea tenemos también el operador de asignación <- que lo que hace es asignar un nombre (la palabra que está a la izquierda) al elemento que está a la derecha. Entonces, esta línea podría traducirse de esta forma: “ponele el nombre datos al elemento gapminder que proviene del paquete gapminder”. Una vez que ejecutamos esta línea, si no hay ningún error, debería crearse en el panel “Environment” un elemento que se llame “datos” y que tenga 1704 observaciones y 6 variables:

3. Explorar la estructura de los datos
Explorar datos no significa todavía analizarlos en profundidad. Implica responder preguntas básicas: cuántas filas hay, qué variables contiene el dataset, qué tipo de valores aparecen.
Algunas funciones clave en esta etapa son:
glimpse(datos)Rows: 1,704
Columns: 6
$ country <fct> "Afghanistan", "Afghanistan", "Afghanistan", "Afghanistan", …
$ continent <fct> Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, …
$ year <int> 1952, 1957, 1962, 1967, 1972, 1977, 1982, 1987, 1992, 1997, …
$ lifeExp <dbl> 28.801, 30.332, 31.997, 34.020, 36.088, 38.438, 39.854, 40.8…
$ pop <int> 8425333, 9240934, 10267083, 11537966, 13079460, 14880372, 12…
$ gdpPercap <dbl> 779.4453, 820.8530, 853.1007, 836.1971, 739.9811, 786.1134, …glimpse() permite ver rápidamente, en la consola, los nombres de las variables, su tipo y algunos ejemplos de valores. Aparecerá algo así:
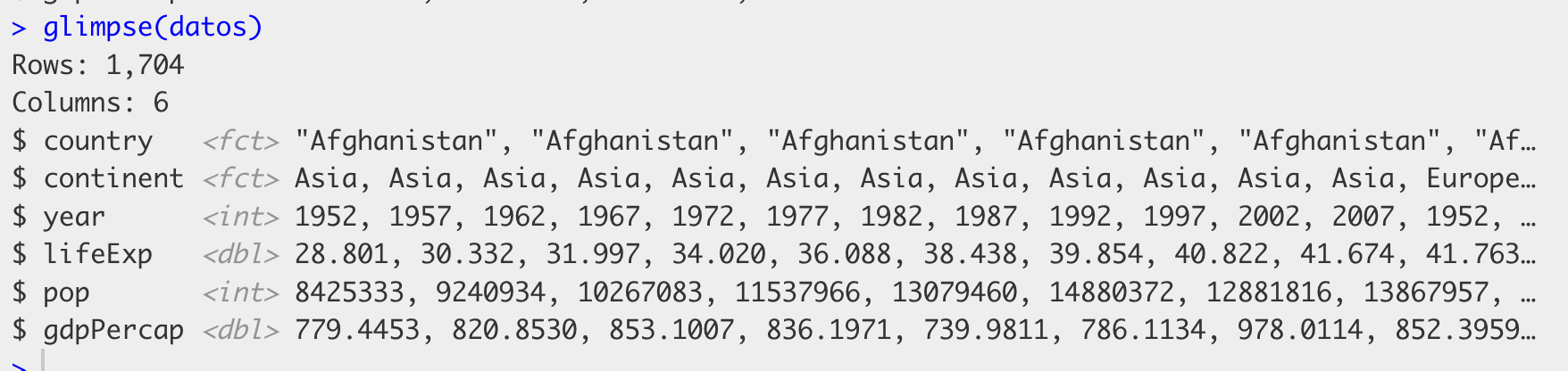
En cada fila de este resultado vemos primero el nombre de las columnas, es decir, de las variables (“country”, “continent”, “year”, etc), a continuación el tipo
En datos de encuestas, esta función ayuda a detectar codificaciones problemáticas o variables que conviene recodificar más adelante.
También es habitual mirar resúmenes generales:
#summary(datos)Este paso inicial evita muchos errores posteriores y ayuda a formular mejores preguntas analíticas.
4. Seleccionar y filtrar: empezar a tomar decisiones
Analizar datos siempre implica elegir. Raramente se trabaja con todas las variables y todos los casos al mismo tiempo.
Para seleccionar columnas relevantes:
#datos_reducidos <- select(datos, edad, sexo, educacion, ingreso)Para filtrar observaciones según algún criterio:
#datos_adultos <- filter(datos_reducidos, edad >= 18)Estas operaciones ya introducen una perspectiva analítica. Definen qué parte de la realidad queda dentro del análisis y cuál queda fuera.
5. Resumir información con sentido analítico
Una vez definidos los datos de interés, suele ser necesario resumirlos. Promedios, medianas, proporciones y conteos son operaciones centrales en el análisis cuantitativo.
Por ejemplo, calcular el ingreso promedio por nivel educativo:
resumen <- datos_adultos %>%
group_by(educacion) %>%
summarise(
ingreso_promedio = mean(ingreso, na.rm = TRUE),
n = n()
)Aquí aparecen varias ideas importantes:
group_by()define la unidad de análisis.summarise()produce nuevas variables resumen.na.rm = TRUEindica cómo tratar los valores faltantes.
El uso del operador %>% permite leer el código como una secuencia de transformaciones, lo que facilita su comprensión y revisión.
6. Reorganizar datos para analizarlos mejor
En muchos datasets, especialmente de encuestas, los datos no están en el formato más conveniente para el análisis o la visualización. Para eso se utilizan funciones de tidyr.
Un caso típico es pasar de un formato ancho a uno largo:
datos_largos <- datos_adultos %>%
pivot_longer(
cols = starts_with("item_"),
names_to = "pregunta",
values_to = "respuesta"
)Este tipo de transformación resulta clave cuando se analizan baterías de preguntas o se quiere comparar patrones entre ítems.
7. Pensar los gráficos como parte del análisis
Graficar no es un paso decorativo. Los gráficos permiten detectar patrones, outliers y relaciones que no siempre aparecen en tablas.
En R, la visualización se apoya en ggplot2, que implementa la llamada gramática de gráficos. La idea central es construir gráficos por capas, definiendo datos, variables estéticas y geometrías.
Un ejemplo simple:
ggplot(datos_adultos, aes(x = educacion, y = ingreso)) +
geom_boxplot()Este gráfico permite comparar la distribución de ingresos según nivel educativo. Incluso con un código breve, ya aparecen decisiones analíticas importantes: qué variable va en cada eje y qué tipo de gráfico se utiliza.
8. Ajustar y refinar visualizaciones
Una vez creado un gráfico básico, suele ser necesario ajustarlo para mejorar su legibilidad.
Por ejemplo, cambiar etiquetas y títulos:
ggplot(datos_adultos, aes(x = educacion, y = ingreso)) +
geom_boxplot() +
labs(
title = "Distribución de ingresos por nivel educativo",
x = "Nivel educativo",
y = "Ingreso mensual"
)También es posible facetar gráficos para comparar grupos:
ggplot(datos_adultos, aes(x = educacion, y = ingreso)) +
geom_boxplot() +
facet_wrap(~ sexo)Estas decisiones no son neutras. Orientan la interpretación y ponen el foco en ciertos contrastes.
9. De los gráficos exploratorios a los gráficos comunicables
No todos los gráficos cumplen la misma función. Algunos sirven para explorar, otros para comunicar resultados a un público más amplio.
Un buen criterio es mantener el código organizado y reproducible, de modo que un gráfico pueda ajustarse fácilmente si cambian los datos o las preguntas de investigación.
Trabajar con scripts bien estructurados y proyectos en RStudio ayuda a sostener este proceso en el tiempo.
10. Un flujo de trabajo integrado
Si miramos el recorrido completo, aparece un patrón:
- Cargar datos reales.
- Explorar su estructura.
- Seleccionar y filtrar.
- Resumir información.
- Reorganizar cuando es necesario.
- Visualizar para analizar y comunicar.
Este flujo no es lineal ni rígido. Muchas veces se vuelve hacia atrás, se ajustan decisiones o se reformulan preguntas. R y tidyverse facilitan este ida y vuelta, dejando registro de cada paso.
Cierre
Empezar a analizar datos cuantitativos en R implica aprender a pensar en términos de procesos y transformaciones. Cada función aplicada a los datos expresa una decisión analítica y cada gráfico propone una forma de mirar la información. Lejos de ser una caja negra, el código permite documentar, revisar y discutir esas decisiones.
Este post buscó ofrecer una guía inicial, suficientemente amplia para orientarse y lo bastante concreta como para ponerse a trabajar. A partir de aquí, el camino se abre hacia análisis más complejos, modelos estadísticos y visualizaciones más elaboradas.